Iterative Methods for Linear Equations
We introduce the basic concepts and components of
iterative methods for
the solution of a system of linear equations , Consider the solution of linear
equation system
Ax = b, A ∈ Rn×n, b ∈ span(A)
![]()
![]()
![]() (4)
(4)
Assume that the null space of A has no nonzero vector. Denote by
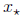 the
the
unique solution. Define
r = r(x) = b - Ax,
as the residual at x with respect to the system (A, b). The residual at
the
exact solution is zero .
The fixed-point iteration
We develop an iterative method as follows. First, a system of linear equations
of (4) can be written in many mathematically equivalent forms , we consider a
particular form involving the residual in order to make corrections,
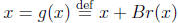 , B is nonsingular:
, B is nonsingular:


 (5)
(5)
We refer to this form as the form of fixed-point equations. We shall see shortly
the role of matrix B.
Next, starting with an initial guess 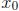 , we obtain iteratively new guesses,
, we obtain iteratively new guesses,
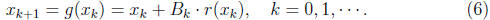
The iteration may or may converge, depending on the
selection of matrix B.
The error in 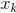 is
is
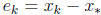 . The iteration converges to the true solution,
. The iteration converges to the true solution,
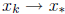 if and only if
if and only if
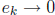 .
.
Convergence analysis
In convergence analysis, we obtain the error propagation equations first from
(5) and (6)

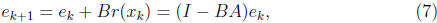
The matrix (I - BA) is the error propagation matrix, it
relates the errors in
two successive iteration steps, and hence relates the error at every step k to
the initial one, 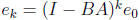 .
.
It is easy to check that the necessary and sufficient condition for the errors
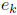 to converge to zero with arbitrary initial guess is
to converge to zero with arbitrary initial guess is
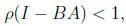
where 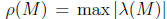 denotes the spectrum radius of matrix M. The
denotes the spectrum radius of matrix M. The
smaller 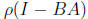 is, the faster the convergence. The extreme case is
is, the faster the convergence. The extreme case is
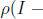
BA) = 0, which means B = A-1 and we are brought back to where we start.
We are left to consider the the remaining case
![]()

In this case, matrix B may be viewed as the inverse of a portion of the matrix
A as we shall see shortly.
A design approach: matrix splittings
We choose the matrix B in the fixed-point iteration to satisfy the convergence
criterion (8). Write A in a split form
A = M - N, M is nonsingular.
![]()
![]()
![]()
![]()
![]() (9)
(9)
We refer to matrix M the splitting matrix. Then, A = M(I - M-1N). Let
B = M-1. Then, (I - BA) = M-1N. The convergence criterion (8) becomes
the following splitting criterion
![]()

The error propagation equation can be rewritten in terms of the split matrices
![]()
![]()
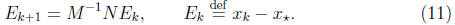
The iteration procedure (6) takes the following specific form,
![]()

We note that computing the right hand side 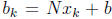 involves matrixvector
involves matrixvector
multiplication and vector addition, the computation of
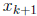 then involves
then involves
the solution of 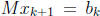 . In splitting, we choose M so that the
. In splitting, we choose M so that the
system can be solved easily .
Iterations Based on Diagonal-Triangular Splitting
Diagonal systems and triangular systems are easy to solve. Many iteration
methods are based on the diagonal-triangular split form of A:
A = D - L - U, ![]()
![]()
![]()
![]() (13)
(13)
where D is diagonal (not necessarily equal to the diagonal portion of A) and
nonsingular, and L is strict lower triangular (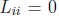 ). In particular, D - L
). In particular, D - L
may be the lower portion of A.
•
Jacobi Iteration: M = D = diag(A).
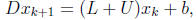
Sufficient condition for convergence: A is diagonally dominant.
•
Gauss-Seidel(GS) Iteration: M = D - L = tril(A).
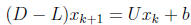
Sufficient condition for convergence: A is diagonally dominant.
•
Successive Over-Relaxation(SOR): M = ω-1(D - ωL), ω is a
scalar.
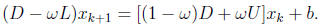
When ω = 1, SOR recovers the GS iteration.
Sufficient condition for convergence : if A is symmetric, positive definite ,
the SOR iteration converges for any ω ∈ (0, 2). There are many studies
on determining the optimal parameter ω.
•
Symmetric SOR(SSOR):
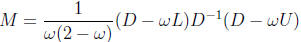
It invokes two successive triangular systems solutions per iteration. Try
to write down the computational procedure.
Is the iteration matrix symmetric when A is spd ?
Remarks.
 In the Jacobi
iteration, all elements are updated at the same time and
In the Jacobi
iteration, all elements are updated at the same time and
the computation can be done in parallel in a trivial way.
In the GS/SOR iteration, the update of the
(i+1)th element depends on
the update of the i-th element, as in the substitution procedure . There
still exists some extent of parallelism in the computation.
The Jacobi iteration and the GS iteration
cost the same in flops per
iteration. Try to find out which one converges faster for a given diagonally
dominant matrix A.
Matrix-vector norms are used in bounding
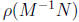 in the convergence
in the convergence
analysis.
The above iterative methods are stationary, i.e., the error propagation
matrix in a method does not change over the iteration procedure. There
are many kinds of non-stationary methods that are found more effective.
In particular, the conjugate gradient method and its variants are used
more often.
| Prev | Next |