Sixth Grade Math
E · Text Messaging Improvement?
On a standard mobile phone the letters are distributed across the keys 2 through
9 as:
| 2 ABC |
3 DEF |
|
| 4 GHI |
5 JKL |
6 MNO |
| 7 PQRS |
8 TUV |
9 WXYZ |
To enter the letter C, you press key 2 three times (seeing
A-B-C). The number of keystrokes to enter
a letter depends on where it is in the list of letters on its key.
The Flathead Telephone Company (FTC) is considering rearranging the letters on
the keys to reduce
the average number of keystrokes required to enter names etc. or send text
messages. The letters
must still appear in alphabetical order on the keys but different numbers of
letters may appear on
each key and possibly more keys could be used. FTC has several databases of
letter frequencies
used in different applications . For instance, it might help to move S from the
7
key to the 8 key. They
need a program which is given the frequencies of the letters and a number of
keys and returns the
assignment of letters to keys with the smallest average number of keystrokes
using the given
frequencies. Each key used must have at least one letter and at most eight
letters.
Input
The first line of input contains a single integer N, (1 ≤ N ≤ 1000) which is the
number of data sets that
follow. Each data set consists of three lines of input. The first line contains
a single integer K, (4 ≤ K
≤ 26), the number of keys which are to be used. The second and third lines
contain 13 decimal
values each giving the percent frequency of the letters A through Z in order.
Output
For each data set, you should generate one line of output with the following
values: The data set
number as a decimal integer (start counting at one), the best average number of
keystrokes to three
decimal places, a space and the letters A through Z, for the best arrangement,
in order with a single
space at the break between letters on different keys. It
is possible that the same input data set may
produce different output.
| Sample Input |
 |
| Sample Output |
| 1 1.647 AB CD EFG HIJK LM NOPQ RS TUVWXYZ 2 1.570 A B CDEFG HIJKLM N OP QR STUV WXYZ |
F · Extended Normal Order Sort
When sorted in standard order, strings with digits in them may not sort to where
they are expected.
For instance, xyz100 precedes xyz2. In some applications such as listing files,
normal order sort
may be used where any string of digits in a character string is treated as a
single digit with numerical
value given by the digit string. For example, the following are in normal order:
XYZ001, XYZ2, XYZ003, XYZ08, XYZ23, XYZ100, XYZQ
We wish to extend normal order sort in two ways :
1. Lower case and upper case letters sort the same (with the upper case value).
2. If a plus (+) or minus (-) sign precedes a digit and does not follow a digit,
it is considered part
of the following number for sorting purposes.
So 123+456+7890 are three numbers separated by plus signs but A+003 is the same
as A3.
To do our sort, we will use a library sort routine but we need to furnish a
comparison routine . Write a
comparison routine which takes as input two strings of printable, non-space
ASCII characters
(chr(33)-chr(126)) and returns:
-1 if the first string should precede the second in extended normal order
0 it the two strings are the same in extended normal order, or
1 if the first string should follow the second in extended normal order.
Input
The first line of input contains a single integer N, (1 ≤ N ≤ 1000) which is the
number of data sets that
follow. Each data set consists of a single line of input containing the two
strings to be compared
separated by a space.
Output
For each data set, you should generate one line of output with the following
values: The data set
number as a decimal integer (start counting at one), a space and –1, 0 or 1
depending on whether the
first string precedes, is the same as, or follows the second string in extended
normal order.
| Sample Input | Sample Output |
 |
|
G · Area of Polycubes
A polycube is a solid made by gluing together unit cubes (one unit on each edge)
on one or more
faces. The figure in the lower-left is not a polycube because some cubes are
attached along an
edge.
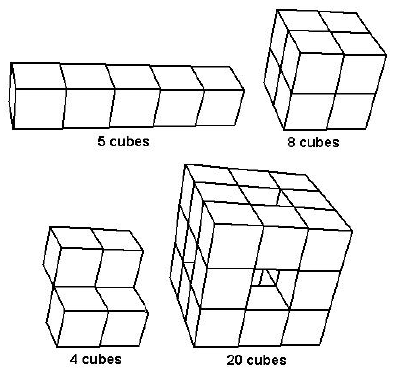
For this problem, the polycube will be formed from unit
cubes centered at integer lattice points in
3-space. The polycube will be built up one cube at a time, starting with a cube
centered at (0,0,0). At
each step of the process (after the first cube), the next cube must have a face
in common with a cube
previously included and not be the same as a block previously included. For
example, a 1-by-1-by-5
block (as shown above in the upper-left polycube) could be built up as:
(0,0,0) (0,0,1) (0,0,2) (0,0,3) (0,0,4)
and a 2-by-2-by-2 cube (upper-right figure) could be built as:
(0,0,0) (0,0,1) (0,1,1) (0,1, 0) (1,0,0) (1,0,1) (1,1,1) (1,1, 0)
Since the surface of the polycube is made up of unit
squares , its area is an integer.
Write a program which takes as input a sequence of integer lattice points in
3-space and determines
whether is correctly forms a polycube and, if so, what the surface area of the
polycube is.
Input
The first line of input contains a single integer N, (1 ≤ N ≤ 1000) which is the
number of data sets that
follow. Each data set consists of multiple lines of input. The first line
contains the number of points P,
(1 = P = 100) in the problem instance. Each succeeding line contains the centers
of the cubes, eight
to a line (except possibly for the last line). Each center is given as 3
integers, separated by commas.
The points are separated by a single space.
Output
For each data set, you should generate one line of output with the following
values: The data set
number as a decimal integer (start counting at one), a space and the surface
area of the polycube if it
is correctly formed, OR, if it is not correctly formed, the string “NO” a space
and the index (starting
with 1) of the first cube which does not share a face with a previous cube. Note
that the surface area
includes the area of any included holes.
| Sample Input | Sample Output |
 |
|
| Prev | Next |