Thank you for visiting our site! You landed on this page because you entered a search term similar to this: charts and graph on the comparison of substitution and linear combination. We have an extensive database of resources on charts and graph on the comparison of substitution and linear combination. Below is one of them. If you need further help, please take a look at our software "Algebrator", a software program that can solve any algebra problem you enter!
- Mean substitution artificially decreases the variation of scores, and this decrease in individual variables is proportional to the number of missing data (i.e., the more missing data, the more "perfectly average scores" will be artificially added to the data set).
- Because it substitutes missing data with artificially created "average" data points, mean substitution may considerably change the values of correlations.
See also, Pairwise Deletion of Missing Data vs. Mean Substitution and Casewise vs. pairwise deletion of missing data
Pareto Distribution. The standard Pareto distribution has density function (for positive parameter c ):
f(x) = c/xc+1 1 ![]() x, c > 0
x, c > 0
where
c is the shape parameter of the distribution.
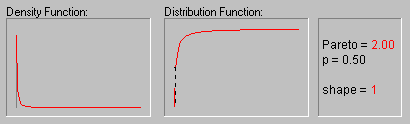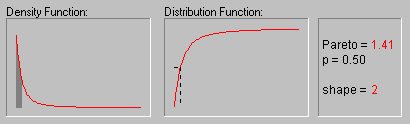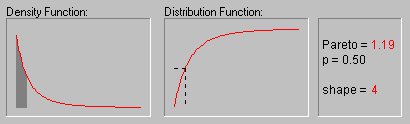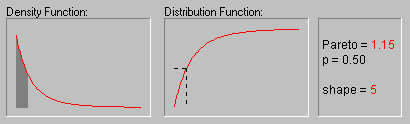
The animation above shows the Pareto distribution for the shape parameter equal to 1, 2, 3, 4, and 5.
Partial Correlation. A correlation between two variables that remains after controlling for (e.g., partialling out) one or more other variables. For example, the HAIR LENGTH may correlate with HEIGHT (with taller individuals having shorter hair), however, that correlation will likely become smaller or even disappear if the influence of GENDER is removed, since women are generally shorter and are more likely to have long hair than men.
See also .
Parzen Window. In Time Series, the Parzen window is a weighted moving average transformation used to smooth the periodogram values. In the Parzen window (Parzen, 1961), for each frequency, the weights for the weighted moving average of the periodogram values are computed as:
wj = 1-6*(j/p)2 + 6*(j/p)3 (for j = 0 to p/2)
wj = 2*(1-j/p)3 (for j = p/2 + 1 to p)
w-j = wj (for j ![]() 0)
0)
where p = (m-1)/2
This weight function will assign the greatest weight to the observation being smoothed in the center of the window, and increasingly smaller weights to values that are further away from the center.
See also, Basic Notations and Principles.
In Neural Networks, the Parzen window is an alternative name for kernel-based approximation techniques, as used in probabilistic neural networks and generalized regression neural networks (Parzen, 1962).
Pearson Correlation. The most widely-used type of correlation coefficient is Pearson r (Pearson, 1896), also called linear or product-moment correlation (the term correlation was first used by Galton, 1888). Using non technical language, one can say that the correlation coefficient determines the extent to which values of two variables are "proportional" to each other. The value of the correlation (i.e., correlation coefficient) does not depend on the specific measurement units used; for example, the correlation between height and weight will be identical regardless of whether inches and pounds, or centimeters and kilograms are used as measurement units. Proportional means linearly related; that is, the correlation is high if it can be approximated by a straight line (sloped upwards or downwards). This line is called the regression line or least squares line, because it is determined such that the sum of the squared distances of all the data points from the line is the lowest possible. Pearson correlation assumes that the two variables are measured on at least interval scales. The Pearson product moment correlation coefficient is calculated as follows:
r12 = [![]() (Yi1 - Y-bar1)*(Yi2 - Y-bar2)] / [
(Yi1 - Y-bar1)*(Yi2 - Y-bar2)] / [![]() (Yi1 - Y-bar1)2 *
(Yi1 - Y-bar1)2 * ![]() (Yi2 - Y-bar2)2]1/2
(Yi2 - Y-bar2)2]1/2
See also, Correlations - Overview.
Pearson Curves. A system of distributions proposed (e.g., see Hahn and Shapiro, 1967, pages 220-224) consists of seven solutions (of 12 originally enumerated by Pearson) to a differential equation which approximate a wide range of distributions of different shapes. Gruska, Mirkhani, and Lamberson (1989) describe in detail how the different Pearson curves can be fit to an empirical distribution. A method for computing specific Pearson percentiles is also described in Davis and Stephens (1983).See also, Johnson Curves.
Percentiles. The percentile (this term was first used by Galton, 1885a) of a distribution of values is a number xp such that a percentage p of the population values are less than or equal to xp. For example, the 25th percentile (also referred to as the .25 quantile or lower quartile) of a variable is a value (xp) such that 25% (p) of the values of the variable fall below that value.Similarly, the 75th percentile (also referred to as the .75 quantile or upper quartile) is a value such that 75% of the values of the variable fall below that value and is calculated accordingly.
Pie Chart. Pie charts (the term first used by Haskell, 1922) are useful for representing proportions. Individual data values of the X variable are represented as the "wedges" of the pie.
Pie Chart - Counts. Unlike the values pie chart, this type of pie (this term was first used by Haskell, 1922) chart (sometimes called frequency pie chart) interprets data like a histogram. It categorizes all values of the selected variable following the selected categorization technique and then displays the relative frequencies as pie slices of proportional sizes.
See also, Pie Charts.
Pie Chart - Multi-pattern Bar. The multi-pattern bar plot is designed to display the same type of data as the values pie chart (see Pie Chart - Values or 2D Histograms), however, the consecutive values are represented by the height of vertical bars (of different colors and patterns) and not areas of pie slices.
Their advantage over pie charts is that they may allow for more precise comparisons between presented values (e.g., small pie slices may be difficult to compare if they are not adjacent). This type of graph may also have advantages over regular histograms (where one fill pattern and color is used for all columns), in cases when quick identification of specific columns is desired.
See also, Pie Charts.
Pie Chart - Values. The sequence of values from the selected variable will be represented by consecutive slices of the pie (this term was first used by Haskell, 1922); the size of each slice will be proportional to the respective value. The values should be greater than 0 (0's and negative values cannot be represented as slices of the pie). This simple type of pie chart (sometimes called data pie chart) interprets data in the most straightforward manner: one case = one slice.
See also, Pie Charts.
Poisson Distribution. The Poisson distribution (the term first used by Soper, 1914) is defined as:
f(x) = (![]() x * e-
x * e-![]() )/x!
)/x!
for x = 0, 1, 2, .., 0 < ![]()
where
![]() (lambda) is the expected value of x (the mean)
(lambda) is the expected value of x (the mean)
e is Euler's constant (2.71...)
Polar Coordinates.
Polar coordinates (r,![]() ) represent the location of a point (in 2D space) by its distance (r) from a fixed point on a fixed line (polar axis) and the angle (
) represent the location of a point (in 2D space) by its distance (r) from a fixed point on a fixed line (polar axis) and the angle (![]() , in radians) from that fixed line.
, in radians) from that fixed line.
Polar plots are used to visualize functions. They also offer an intuitive way to present relations involving a variable representing direction.
See also, Cartesian Coordinates.
Polynomial. This fits to the data, a polynomial function of the form:
y = b0 + b1x + b2x2 + b3x3 + ... + bnxn
where n is the order of the polynomial.
Fitting centered polynomial models via Multiple Regression. The fitting of higher-order polynomials of an independent variable with a mean not equal to zero can create difficult numerical problems. Specifically, the polynomials will be highly correlated due to the mean of the primary independent variable. With large numbers (e.g., Julian dates), this problem is very serious, and if proper protections are not put in place, can cause wrong results! The solution is to "center" the independent variable (sometimes, this procedures is referred to as "centered polynomials"), i.e., to subtract the mean, and then to compute the polynomials. See, for example, the classic text by Neter, Wasserman, & Kutner (1985, Chapter 9), for a detailed discussion of this issue (and analyses with polynomial models in general).
Positive Correlation. The relationship between two variables is such that as one variable's values tend to increase, the other variable's values also tend to increase. This is represented by a positive correlation coefficient.
See also, Correlations - Introductory Overview.
Post hoc Comparisons. Usually, after obtaining a statistically significant F test from the ANOVA, one wants to know which means contributed to the effect; that is, which groups are particularly different from each other. One could of course perform a series of simple t-tests to compare all possible pairs of means. However, such a procedure would capitalize on chance. The reported probability levels would actually overestimate the statistical significance of mean differences. For example, suppose you took 20 samples of 10 random numbers each, and computed 20 means. Then, take the group (sample) with the highest mean and compare it with that of the lowest mean. The t-test for independent samples will test whether or not those two means are significantly different from each other, provided that they were the only two samples taken. Post-hoc comparison techniques on the other hand, specifically take into account the fact that more than two samples were taken. They are used as either hypothesis testing or exploratory methods.
For more information, see the ANOVA chapter.
Post Synaptic Potential (PSP) function. The function applied by a unit to its inputs, weights and thresholds to form the unit's input (or activation) level. The two major PSP functions are linear (weighted sum minus threshold) and radial (scaled squared distance of weight vector from input vector).
See also, Neural Networks.
Prediction Profiles. When the results of an experiment are analyzed, the observed responses on the dependent variables can be fit to a separate prediction equation for each dependent variable (containing different coefficients but the same terms). Once these equations are constructed, predicted values for the dependent variables can be computed at any combination of levels of the predictor variables. A prediction profile for a dependent variable consists of a series of graphs, one for each independent variable, of the predicted values for the dependent variable at different levels of one independent variable, holding the levels of the other independent variables constant at specified values. Inspecting the prediction profiles for the dependent variables can show which levels of the predictor variables produce the most desirable predicted responses on the dependent variables.
For a detailed description of prediction profiles and desirability profiles see Profiling Predicted Responses and Response Desirability.
Predictive Mapping. One application of multiple correspondence analysis is to perform the equivalent of a Multiple Regression for categorical variables, by adding supplementary columns to a design matrix (see also Burt tables). For example, suppose you had a design matrix containing various categorical indicators of health related behaviors (e.g., whether or not the individual smoked, exercised, etc.). You could add two columns to indicate whether or not the respective subject had or had not been ill over the past year (i.e., you could add one column Ill and another column Not ill, and enter 0's and 1's to indicate each subject's health status). If in a simple correspondence analysis of the design matrix, you added those columns as supplementary columns to the analysis, then (1) the summary statistics for the quality of representation (see the Correspondence Analysis Overview) for those columns would give you an indication of how well you can "explain" illness as a function of the other variables in the design matrix, and (2) the display of the column points in the final coordinate system would provide an indication of the nature (e.g., direction) of the relationships between the columns in the design matrix and the column points indicating illness. This technique (adding supplementary points to a multiple correspondence analysis) is also called predictive mapping.
Principal Components Analysis. A linear dimensionality reduction technique, which identifies orthogonal directions of maximum variance in the original data, and projects the data into a lower-dimensionality space formed of a sub-set of the highest-variance components (Bishop, 1995).
See also, Factor Analysis and Neural Networks.
Prior Probabilities. Proportionate distribution of classes in the population (in a classification problem), especially where known to be different than the distribution in the training data set. Used to modify probabilistic neural network training in neural networks.
Probabilistic Neural Networks (PNN). A type of neural network using kernel-based approximation to form an estimate of the probability density functions of classes in a classification problem. One of the so-called Bayesian networks (see Speckt, 1990; Patterson, 1996; Bishop, 1995).
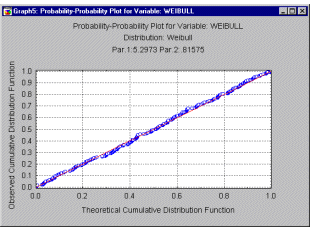
Probability-Probability Plots. You can visually check for the fit of a theoretical distribution to the observed data by examining the probability-probability plot (also called Probability Plot, see example below). In probability- probability plots (or P-P plots for short) the observed cumulative distribution function is plotted against the theoretical cumulative distribution function. As in the Quantile-Quantile plot, the values of the respective variable are first sorted into ascending order. The ith observation is plotted against one axis as i/n (i.e., the observed cumulative distribution function), and against the other axis as F(x(i)), where F(x(i)) stands for the value of the theoretical cumulative distribution function for the respective observation x(i). If the theoretical cumulative distribution approximates the observed distribution well, then all points in this plot should fall onto the diagonal line.
Probability-Probability Plots - Categorized. In this graph, you can visually check for the fit of a theoretical distribution to the observed data by examining each probability-probability plot (also called Probability Plot, see also Probability-Probability Plots) for the respective level of the grouping variable (or user-defined subset of data). In probability-probability plots (or P-P plots for short) the observed cumulative distribution function is plotted against the theoretical cumulative distribution function. As in the Categorized Quantile-Quantile plot, the values of the respective variable are first sorted into ascending order. The ith observation is plotted against one axis as i/n (i.e., the observed cumulative distribution function), and against the other axis as F(x(i)), where F(x(i)) stands for the value of the theoretical cumulative distribution function for the respective observation x(i). If the theoretical cumulative distribution approximates the observed distribution well, then all points in this plot should fall onto the diagonal line. One component graph is produced for each level of the grouping variable (or user-defined subset of data) and all the component graphs are arranged in one display to allow for comparisons between the subsets of data (categories).
Process Analysis. In industrial settings, Process Analysis refers to a collection of analytic methods which can be used to ensure adherence of a product to quality specifications. These methods include Sampling Plans, Process (Machine) Capability Analysis, fitting measurements to Non-Normal Distributions, analysis of Gage Repeatability and Reproducibility and Weibull and Reliability/Failure Time Analysis.
For more information, see the Process Analysis chapter.
Pruning (in Classification Trees). Pruning a classification tree refers to the use of the automatic "right-sized" tree selection procedures developed by Breiman et. al. (1984). These procedures are designed to find, without relying on subjective judgment, the "right-sized" classification tree, that is, a classification tree with an appropriate number of splits and optimal predictive accuracy. The process of determining the "right-sized" classification tree is described in the Computational Methods section of the Classification Trees chapter.
Pseudo-components. Pseudo-components are transformed values of the components (plotted in Ternary graphs) where:
x'i = (xi-Li)/(Total-L)
Here, x'i stands for the ith pseudo-component, xi stands for the original component value, Li stands for the lower constraint (limit) for the ith component, L stands for the sum of all lower constraints (limits) for all components in the design, and Total stands for the mixture total. This transformation makes the coefficients for different factors comparable in size.
(See Cornell, 1993, Chapter 3).
Pseudo-Inverse Algorithm. An algorithm to efficiently optimize a linear model; also known as singular value decomposition (see Bishop, 1995; Press et. al., 1992; Golub and Kahan, 1965).
STATISTICA is a trademark of StatSoft, Inc.